Ericsson ML Challenge Winning Solution | asingleneuron
Ericsson ML Challenge was focused on NLP and Predictive Analytics problem.
This was a two round challenge. First round was online round, top participants from first round called for offline round at Ericsson office to present their approach and thought process to solve these problems to the Jury.
I won the hackathon by securing 2nd place after the offline round.
Problem Statement 1: PREDICT MATERIAL TYPE
Assume that you are a member of a marketing agency and you are given a dataset having the title, subjects, and other features, based on which you have to predict what will be the material of to-be-published research so that you can tie-up with an ideal publisher and help them grow.
TRAINING DATA contains 31653 rows and 12 features
TEST DATA contains 21102 rows and 11 features

The following are the material types:
- Book
- Sound disc
- Videocassette
- Sound cassette
- Music
- Mixed
- CR
This is a multi-class classification problem, we are having 7 different classes for material type to predict.
UNDERSTAND THE DATA:
TARGET:

From the target distribution its very clear data this is an imblanced dataset. All the target classes are not equally distributed. BOOK is the dominating class and CR is the minor one.
From the above distribution we can also guess that ML model can learn patterns for BOOK, SOUNDDISC, VIDEODISC, VIDEOCASS and SOUNDCASS but it can struggle to learn patterns for MUSIC, MIXED and CR classes.
UsageClass, CheckoutType, CheckoutYear, CheckoutMonth:

Above plot is about frequency distribution of UsageClass, CheckoutType, CheckoutYear and CheckoutMonth features.
Form the plot it is very clear that they all have single value.
For example:
UsageClass has only Physical category for all of the observation of dataset.
CheckoutType has only Horizon category.
All these features have 0 variance. This make a conclusion that we can drop these features, because ML model will not learn anything from these features.
Frequency Distribution of Checkouts Vs MaterialType:


From the above two plots its very clear that Checkouts has some relationship with MaterialType.
Frequency Distribution of Creator Vs MaterialType:

Above plots confirms the relationship between Creator and MaterialType feature. For example: Rylant, Cynthia is the author of approx 16 BOOK. So if in the test data model finds Rylant, Cynthia as an author there is a high chances of predicting that observation as BOOK.
Frequency Distribution of Publisher Vs MaterialType:

Above plot represents the relationship between Publisher and MaterialType. For example , Random House has published 114 BOOKS and Warner Home Video has published approx 37 VIDEODISC.
Feature Distribution of Subject Vs MaterialType:

Above distribution plots describe the relationship between Subject and MaterialType.
For example: class VIDEODISC and VIDEOCASS has Fearure Films as a subject (approx 182 counts for VIDEODICS and approx 46 counts for VIDEOCASS)
All of these distribution plots confirms features like Subject, Publisher, Creator, Checkouts has relationship with Target (MaterialType) . We should use all of these feature to train ML model.
Analyze Title feature for different class:
Lets try to find the most common words in Title for different class like BOOK, VIDEODISC and SOUNDDISC.

Above image represents the most common words present in Title feature for BOOK material type.
As we can see common words like novel, book, illustrated , guide, story, stories are presents in the Titles and definitely they show the relationship with BOOK material type.


Above two image represents SOUNDDISC and VIDEODISC most common words present in the Title feature.
Words like video recording, production, screenplay, film, directed has relationship with VIDEODISC and words like sound recording , music, song, soundtrack definitely denotes SOUNDDISC material type.
IMPUTING MISSING VALUES:
Missing values in train and test dataset are as follows :-

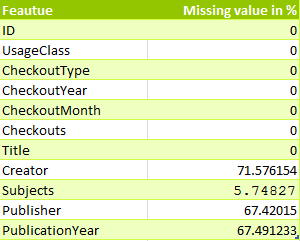
I have used nopublisher, nocreator and nosubject to fill missing values.
df['Publisher'].fillna("nopublisher", inplace=True) df_test['Publisher'].fillna("nopublisher", inplace=True) df['Creator'].fillna("nocreator", inplace=True) df_test['Creator'].fillna("nocreator", inplace=True) df['Subjects'].fillna("nosubject", inplace=True) df_test['Subjects'].fillna("nosubject", inplace=True)
FEATURE ENGINEERING PIPELINE :

I have used the feature engineering creation pipeline as explained in the above picture.
- Create INFO feature by concatenating Title, Subjects, Creator, Publisher features.
- Do text normalization, converting into lowercase.
- Clean extra spaces
- Remove punctuation and special characters.
- Create word tokens
- Pass clean tokens to TfidfVectorizer
TfidfVectorizer(tokenizer=tokenize, ngram_range=(1,2), max_df=0.5, max_features=5000, use_idf=False)
- Find text length of INFO feature
- Find word counts of INFO feature
- Encode Subjects, Creator, Publisher into numerical representation by using LabelEncoder.
- Use Checkouts also
- Finally we will get 5006 features
ML MODEL:
I have designed the ML model as follows :-

As described above , I am using the OOF (out of fold prediction) approach because during analysis phase I have seen some randomness in validation score. So I thought of creating an ensemble of 5 XGBClassifier.
- After getting the features from feature engineering pipeline, I have split the data into 5 folds using StratifiedKFold.
- Train 5 different XGBClassifier by holding out one fold for validation and 4 folds for training the model.
- Do the prediction by using 5 different trained XGBClassifier(max_depth=6).
- Also using early stopping of 10 rounds.
- Average them together and make the final prediction.
- This approach gave me stable results.
PROBLEM STATEMENT 2: PREDICT RATING
Data have been extracted from a website that provides job reviews. The website wants to analyze texts and the corresponding rating that is provided by the user about startups. A research team wants to analyze the liability of the review. In other words, they want to verify whether texts correspond as the same as the score that is provided as the rating for a startup. This task helps the website to rank the user's reviews or ratings.
Your task is to predict the overall rating of reviews.
TRAINING DATA contains 30336 rows and 17 features
TEST DATA contains 29272 rows and 16 features

Approach to solve this problem is almost same as the previous one. This is also a multi-class classification problem. We need to predict Overall rating. That goes from 1 to 5.
UNDERSTAND THE DATA:

Different Features Vs Overall :


Analyzing SUMMARY feature for Overall rating 5:

IMPUTING MISSING VALUES:
Missing values in train and test dataset are as follows:-


I have imputed "nocomments" for summary, positives, negatives and advice_to_mgmt features.
for col in ['summary', 'positives', 'negatives', 'advice_to_mgmt']: print(col) df[col].fillna("nocomments", inplace=True) df_test[col].fillna("nocomments", inplace=True)
Imputed most frequent "mode" values for score features.
for i in range(1,6): col = "score_"+str(i) mode_fill = df[col].mode()[0] print(col ,":", mode_fill) df[col] = df[col].fillna(mode_fill) df_test[col] = df_test[col].fillna(mode_fill)
score_1 : 4.0
score_2 : 5.0
score_3 : 5.0
score_4 : 5.0
score_5 : 4.0
MODEL PIPELINE:

Pipeline for this problems as :
- Create INFO feature by concatenating summary, positives, negatives, advice_to_mgmt features.
- Do text normalization, converting into lowercase.
- Clean extra spaces
- Remove punctuation and special characters.
- Create word tokens
- Pass clean tokens to TfidfVectorizer
TfidfVectorizer(tokenizer=tokenize, ngram_range=(1,2), max_df=0.6, max_features=5000, use_idf=False)
- Encode Place, Location, Status, Job_title features into numerical representation by using LabelEncoder.
- Use all score features
- Finally we will get 5010 features
- Pass these features into single XGBClassifier(max_depth=4, n_estimators = 100)
- Predict the Overall Score on test data by using trained XGBClassifier.
GITHUB REPO contains the code.
Please feel free to comment your suggestions/feedback. THANK YOU !!


Any link to the code ?
ReplyDeleteI will ask the organizers , if I am allowed to share
Deletegreat approach , can you explain the text prepossessing steps in a bit detail please?
ReplyDeleteMore specifically length of text considered , Lemmatization , does the order of concatenation matters ? Any reason for not using the pre trained embeddings? and how did you tackled the imbalance in the dataset ?
DeleteHi Aditya, I tried lemmatization, and re-ordering the concatenation but did not get any improvement . So i dropped that idea. I also tried LSTM but XGBClassifier results were better. For any deep neural network , we should have large amount of data. Dataset was not that much huge. Because of time constraints i did not try to handle imbalance , but we should try this as an experiment of improvement.
DeleteCan you please share the dataset about the above Case Studies?
ReplyDeleteProblem 2 )
DeletePredicting the Publication Material -
https://www.kaggle.com/city-of-seattle/seattle-checkouts-by-title
a small part of the above dataset was used
You can attempt the same problem on
https://www.hackerearth.com/ru/problem/machine-learning/predict-the-publishing-material-type-4/
p.s - the scoring metric is bit different than the actual competition (in actual competition they had Weighted F1 score as metric)
dataset for Problem 1 )
Predicting the Rating on glassdoor ->
http://student.bus.olemiss.edu/files/conlon/mis409/Notes/DataRobot/google-amazon-facebook-employee-reviews/
One thing that was important was the technique to counter the imbalance
And once again congrats Shobhit , i am sure you can share the code on github implementing the same logic on a similar dataset or it will be better if you use the kaggle kernels .
Dataset was almost similar what you have mentioned but with some encoding or re-ordering so that participants can't use the same dataset available on kaggle or glassdoor.
DeleteDue to time constrains , because i entered in the competition very late i did not got time to try handling imbalance.
Problem 2 )
ReplyDeletePredicting the Publication Material -
https://www.kaggle.com/city-of-seattle/seattle-checkouts-by-title
a small part of the above dataset was used
You can attempt the same problem on
https://www.hackerearth.com/ru/problem/machine-learning/predict-the-publishing-material-type-4/
p.s - the scoring metric is bit different than the actual competition (in actual competition they had Weighted F1 score as metric)
dataset for Problem 1 )
Predicting the Rating on glassdoor ->
http://student.bus.olemiss.edu/files/conlon/mis409/Notes/DataRobot/google-amazon-facebook-employee-reviews/
One thing that was important was the technique to counter the imbalance
And once again congrats Shobhit , i am sure you can share the code on github implementing the same logic on a similar dataset or it will be better if you use the kaggle kernels .
Let me try to put the same logic on kaggle and glassdoor dataset. I will share the code or kernel.
DeleteCan you please tell me what was your score for problem 2 ?
ReplyDeleteI got 0.3892 for second problem
DeleteSecond problem , I mean to say predict rating one
Delete